
1. 限流(Rate Limiting):先画红线,再谈弹性
1.1 为什么要限流
当上游流量突增 > 下游容量时,系统会出现级联恶化:线程池耗尽、CPU thrashing、TCP backlog 堆积,最终 OOM。限流的本质是提前丢弃或延迟过量请求,防止系统进入不可恢复状态。
1.2 指标:QPS、TPS 还是并发?
| 指标 | 定义 | 适用场景 | 与 TPS 差异 |
|---|---|---|---|
| QPS | Queries per Second | 读多写少的查询系统 | 1 query ≠ 1 transaction |
| TPS | Transactions per Second | 金融、电商下单 | 一次事务可能含多次 query |
| HPS | HTTP Requests per Second | API Gateway 计费 | 包括静态资源 |
| 并发 | In-flight requests | 线程池/连接池瓶颈 | 与 RT 成反比 |
经验:网关层用 HPS / QPS,服务内部用 并发线程数;TPS 仅在压测或账务场景使用。
1.3 算法对比与选型
| 算法 | 突发能力 | 内存占用 | 分布式实现 | 适用场景 |
|---|---|---|---|---|
| 固定窗口 | 无 | 低 | 容易 | 日志收集、离线批处理 |
| 滑动窗口 | 有(窗口内突发) | 中 | 中等 | 通用,Sentinel 默认 |
| 漏桶 | 无 | 低 | 困难(需要全局队列) | 流量整形、计费 |
| 令牌桶 | 有(桶容量突发) | 低 | 容易(Redis + Lua) | 常规业务,Guava、Resilience4j |
滑动窗口与令牌桶并非互斥:
滑动窗口解决“时间边界”问题;
令牌桶解决“突发/空闲补偿”问题。
> 生产环境常见组合:网关层滑动窗口 + 服务内部令牌桶。
1.3.1 固定窗口计数器
在固定时间窗口内计数,超过阈值则拒绝请求。这是最简单的方法,比如每秒接受100个请求,如果一秒内超过100个请求就抛弃。
但是这种方法存在两个问题:
- 单位时间很难把控。如下图所示,从下边看每秒请求数没有超过100,但是从上边看每秒请求数超过了100。
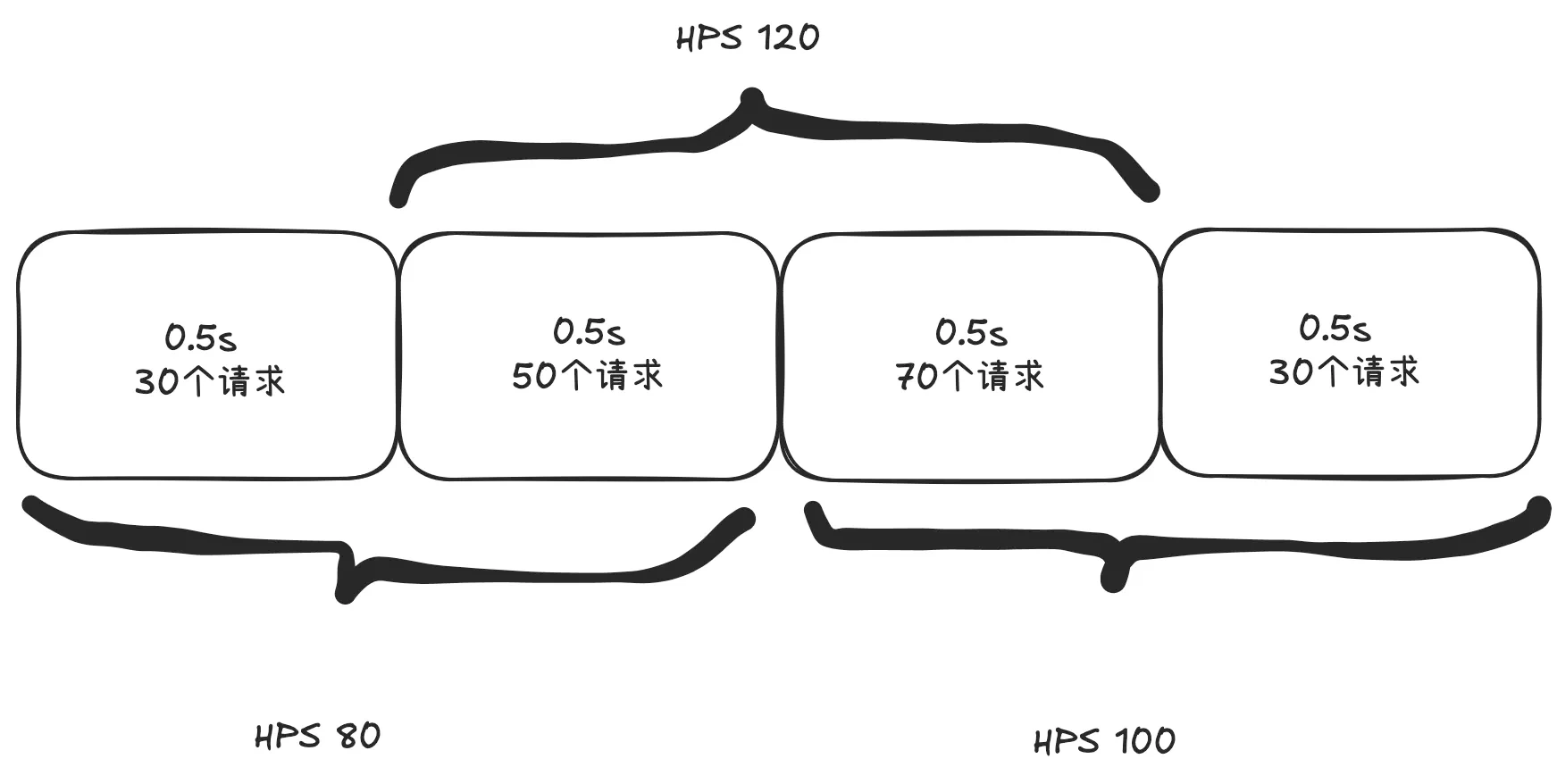
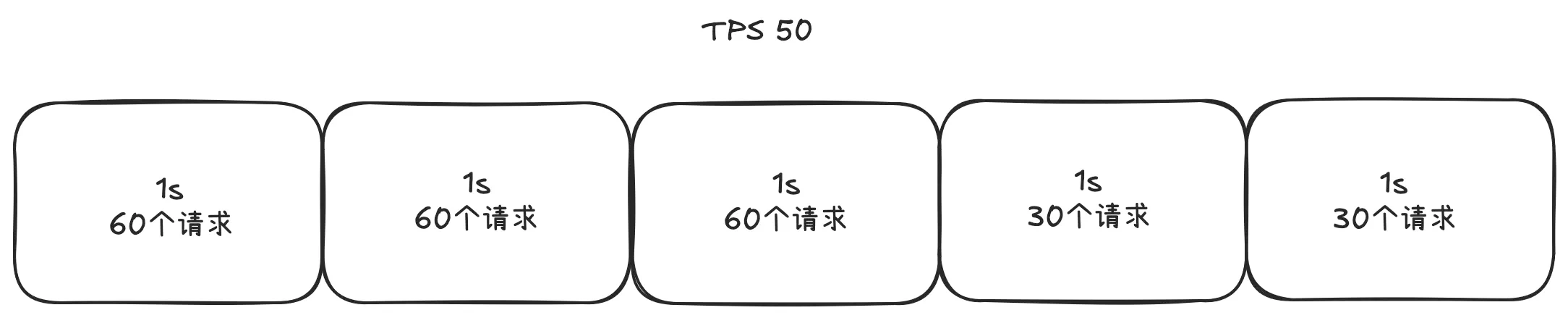
- 有一段时间流量超了,但是也不一定需要限流。如下如所示,虽然前三秒看起来流量超了,但是如果接口的读超时时间是5秒的话就不需要限流。
1.3.2 滑动时间窗口
将时间划分为多个小窗口,滑动统计请求数,更精确地控制流量。滑动窗口是目前最主流的限流方法。
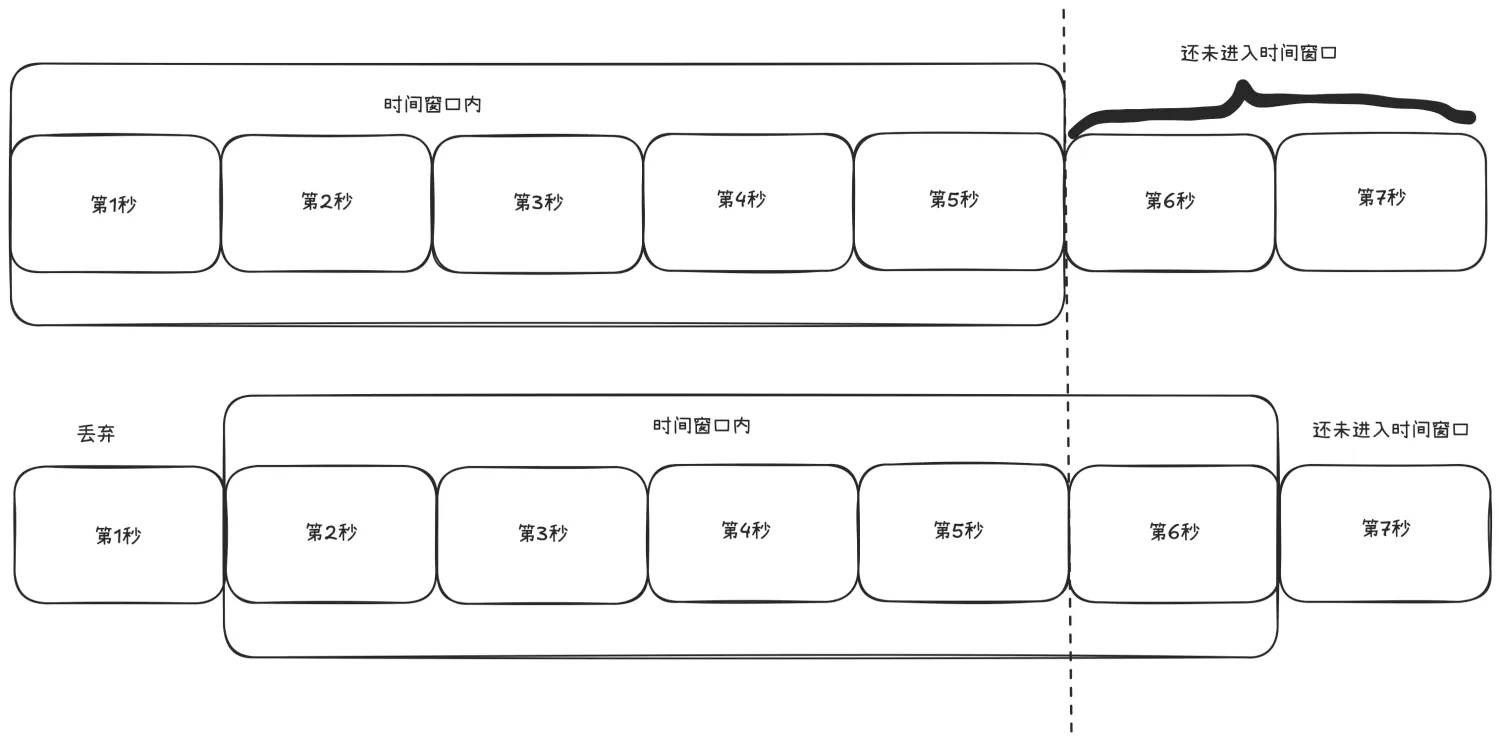
开始的时候,我们把t1~t5看做一个时间窗口,每个窗口1s,如果我们定的限流目标是每秒50个请求,那t1~t5这个窗口的请求总和不能超过250个。
这个窗口是滑动的,下一秒的窗口成了t2~t6,这时把t1时间片的统计抛弃,加入t6时间片进行统计。这段时间内的请求数量也不能超过250个。
滑动时间窗口的优点是解决了固定窗口计数器算法的缺陷,但是也有2个问题:
- 流量超过就必须抛弃或者走降级逻辑。
- 对流量控制不够精细,不能限制集中在短时间内的流量,也不能削峰填谷。
1.3.3 漏桶算法(Leaky Bucket)
以固定速率处理请求,超出部分排队或丢弃,适用于平滑处理流量。
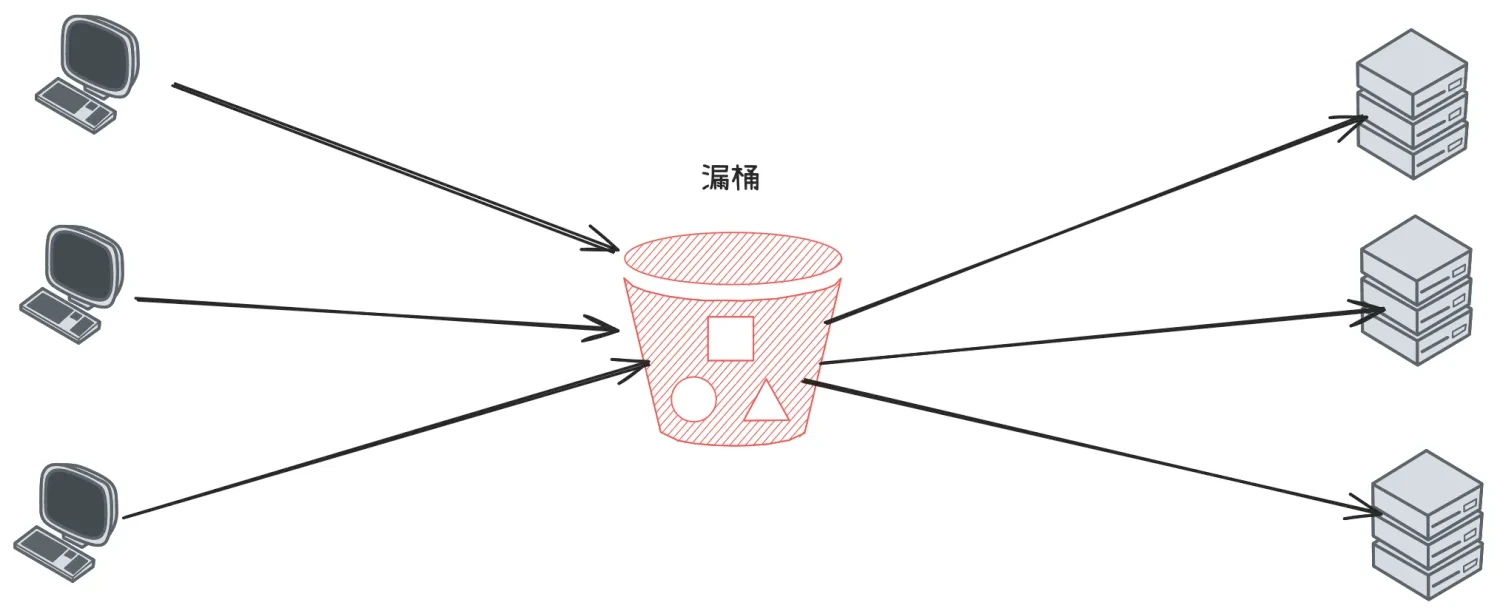
在客户端的请求发送到服务器之前,先用漏桶缓存起来,这个漏桶可以是一个长度固定的队列,这个队列中的请求均匀的发送到服务端。
如果客户端的请求速率太快,漏桶的队列满了,就会被拒绝掉,或者走降级处理逻辑。这样服务端就不会受到突发流量的冲击。
漏桶算法的优点是实现简单,可以使用消息队列来削峰填谷。
但是也有3个问题需要考虑:
- 漏桶的大小,如果太大,可能给服务端带来较大处理压力,太小可能会有大量请求被丢弃。
- 漏桶给服务端的请求发送速率。
- 使用缓存请求的方式,会使请求响应时间变长。
漏桶大小和发送速率这2个值在项目上线初期都会根据测试结果选择一个值,但是随着架构的改进和集群的伸缩,这2个值也会随之发生改变。
1.3.4 令牌桶算法(Token Bucket)
以固定速率生成令牌,请求需获取令牌后才能被处理,适用于允许突发流量的场景。 令牌桶算法就跟病人去医院看病一样,找医生之前需要先挂号,而医院每天放的号是有限的。当天的号用完了,第二天又会放一批号。
算法的基本思想就是周期性的执行下面的流程:
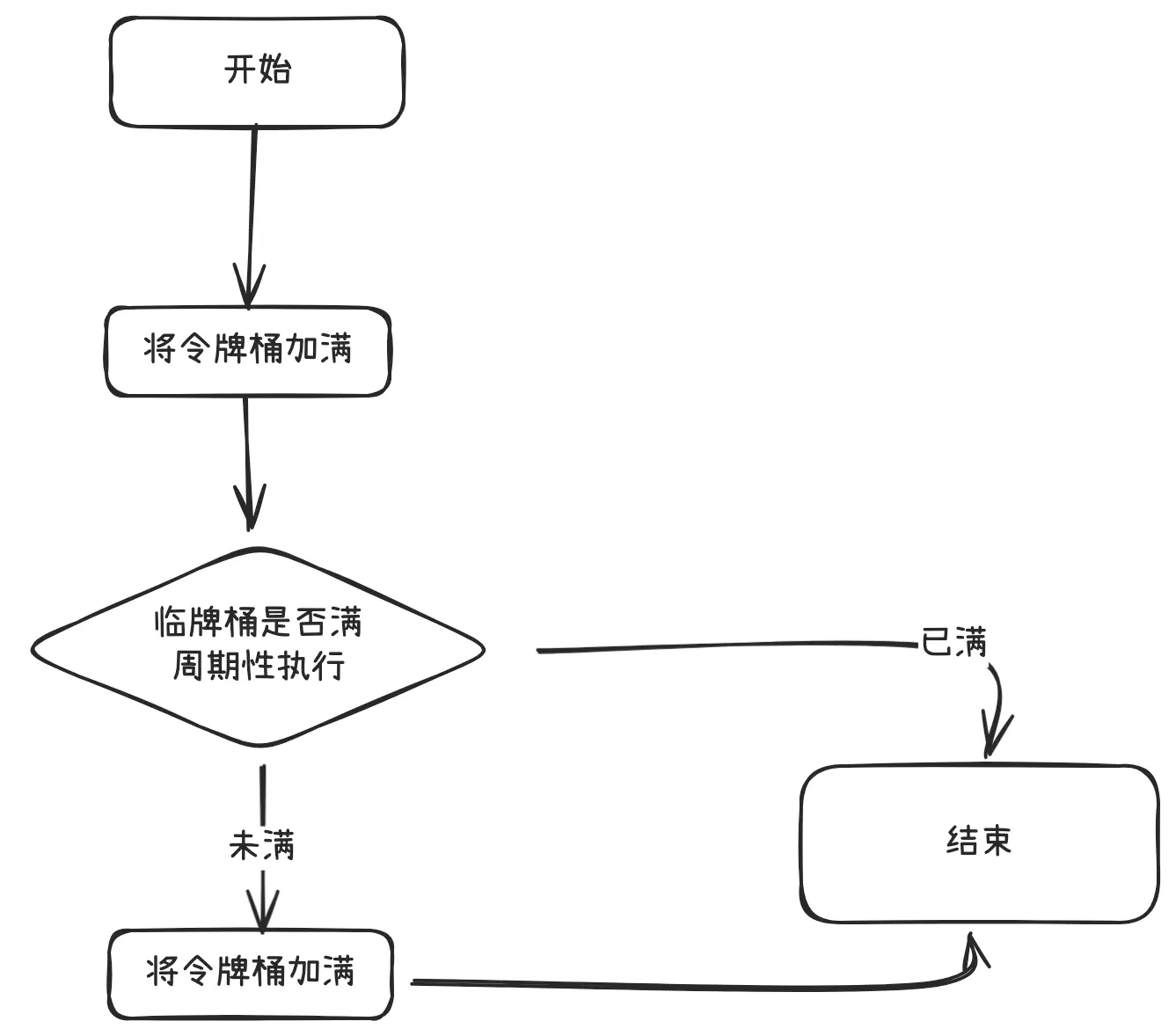
客户端在发送请求时,都需要先从令牌桶中获取令牌,如果取到了,就可以把请求发送给服务端,取不到令牌,就只能被拒绝或者走服务降级的逻辑。如下图:
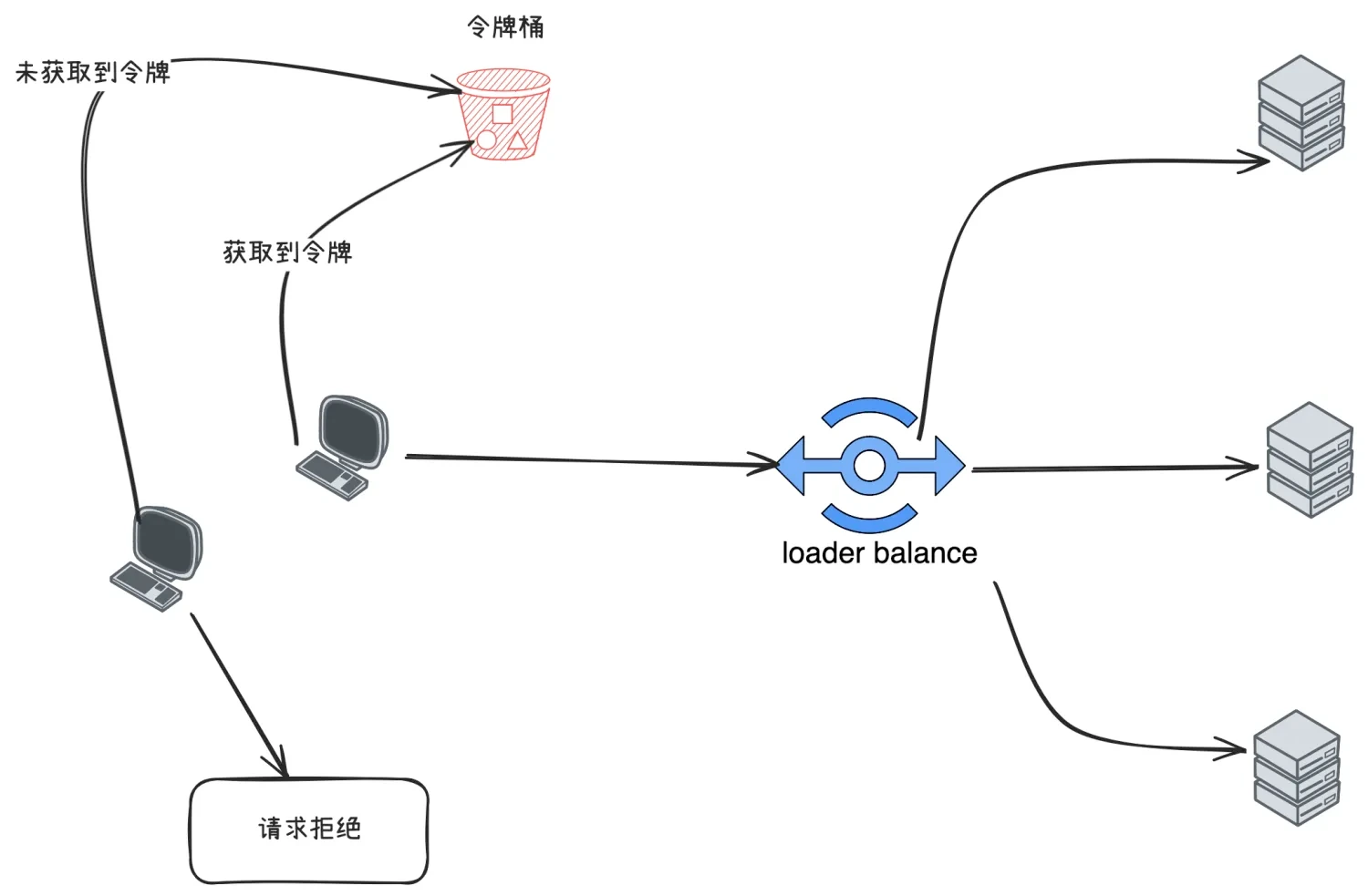
令牌桶算法解决了漏桶算法的问题,而且实现并不复杂,使用信号量就可以实现。在实际限流场景中使用最多,比如google的guava中就实现了令牌桶算法限流。
1.3.5 分布式限流
如果在分布式系统场景下,上面介绍的4种限流算法是否还适用呢?
以令牌桶算法为例,假如在电商系统中客户下了一笔订单,如下图:
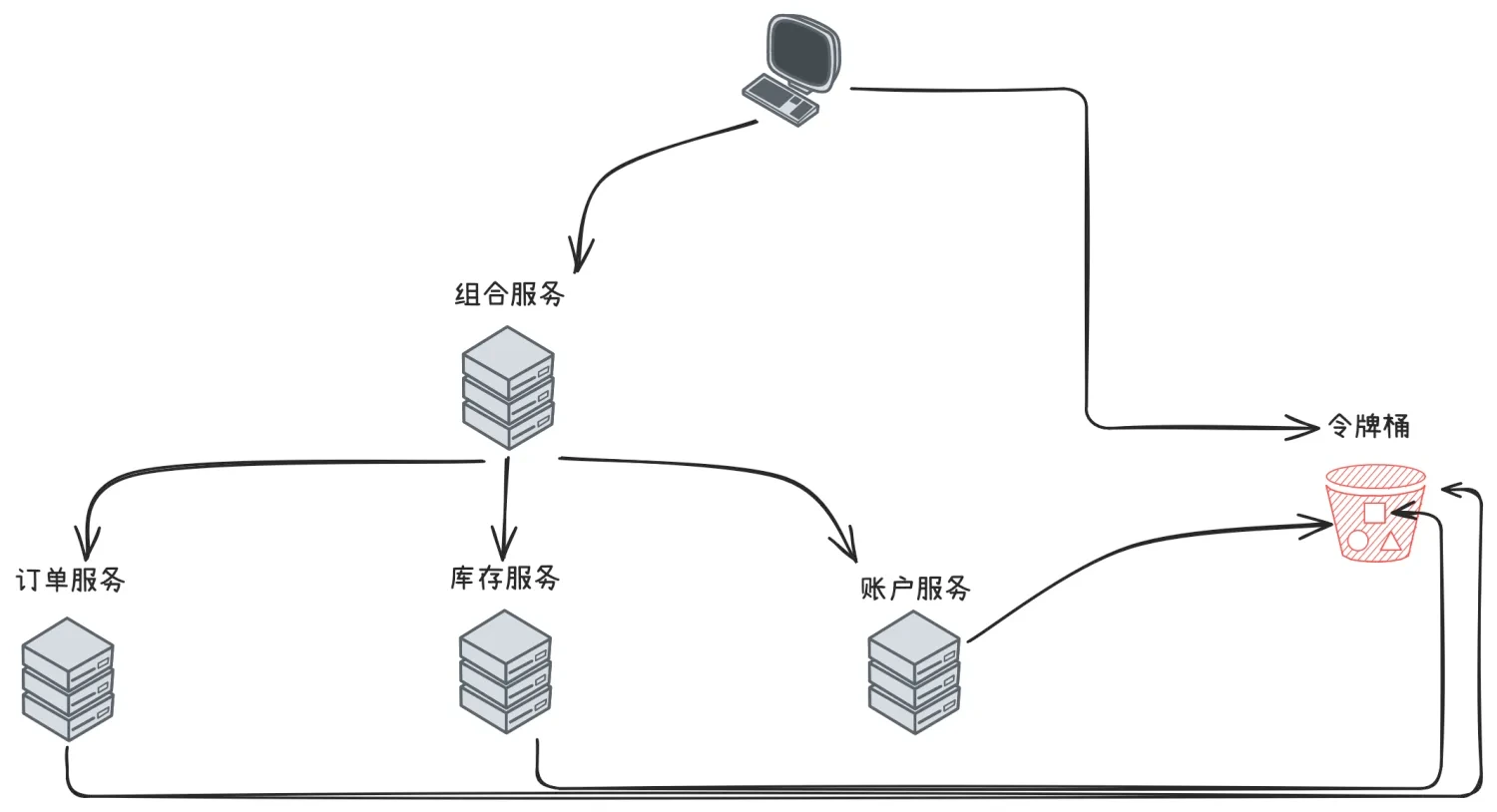
如果我们把令牌桶单独保存在一个地方(比如redis中)供整个分布式系统用,那客户端在调用组合服务,组合服务调用订单、库存和账户服务都需要跟令牌桶交互,交互次数明显增加了很多。
有一种改进就是客户端调用组合服务之前首先获取四个令牌,调用组合服务时减去一个令牌并且传递给组合服务三个令牌,组合服务调用下面三个服务时依次消耗一个令牌。
1.3.6 hystrix限流
hystrix可以使用信号量和线程池来进行限流。但是Netflix在2018年宣布部分组件进入维护状态,只修改bug不在更新,后续spring cloud宣布,spring cloud Netflix项目进入维护状态,并在2020年移除相关的Netflix OSS组件,因此不在推荐使用。
1.3.7 Sentinel限流
Sentinel 的限流机制主要基于滑动窗口算法,通过监控资源的实时请求速率(如 QPS)或并发线程数,当达到设定的阈值时,对超出部分的请求进行限制,以防止系统过载。
其工作流程如下:
- 请求拦截:在业务方法执行前,通过 SphU.entry(resource) 方法对资源进行拦截。
- 规则校验:根据预设的限流规则,判断当前请求是否超过阈值。
- 处理结果: 若未超过阈值,允许请求通过。 若超过阈值,抛出 BlockException,可通过定义 blockHandler 方法进行处理。
- 资源释放:请求处理完成后,调用 entry.exit() 释放资源。
这种设计体现了快速失败原则(Fail-Fast Principle),强调在面对错误或异常情况时,系统应该尽早地检测并快速失败,避免故障进一步扩大,从而提高系统的稳定性和可靠性。
限流模式
Sentinel 提供了多种限流模式,以满足不同的业务需求:
- QPS 模式:限制每秒钟的请求数量。
- 线程数模式:限制同时处理的线程数。
- 关联限流:当关联资源达到阈值时,对当前资源进行限流。
- 链路限流:根据调用链路进行限流,避免某条链路上的资源过载。
- 热点参数限流:对特定参数值进行限流,防止某些热点参数导致系统过载。
- 集群限流:在分布式环境下,对多个节点进行统一的限流控制。
限流算法
Sentinel 的限流实现主要基于滑动窗口算法,同时也支持漏桶和令牌桶等算法,以适应不同的流量控制需求:
- 滑动窗口算法:将时间划分为多个小窗口,实时统计请求数量,适用于平滑处理流量波动。
- 漏桶算法:以固定速率处理请求,超出部分排队或丢弃,适用于平滑处理流量。
- 令牌桶算法:以固定速率生成令牌,请求需获取令牌后才能被处理,适用于允许突发流量的场景。
通过这些算法,Sentinel 能够灵活地应对各种流量控制场景,保障系统的稳定运行。
1.4 分布式限流的关键细节
-
令牌桶放哪里?
Redis+Lua(原子自增 + TTL)是最轻量的方案,单分片 10W RPS 无压力。- 多分片场景可用
Redisson+RRateLimiter或 Sentinel Cluster Flow Rule。
-
网络放大问题 令牌桶放在远程节点,每次请求都跨网络。
- 采用 批量预取(credit-based):客户端一次拉 100 个令牌,本地消费完再拉。
- 或者使用 代理网关(Envoy、Nginx)统一限流,后端不再关心。
1.5 落地清单
- Java:Sentinel(热点参数、链路限流)、Bucket4j(JSR-107 兼容)。
- Go:uber-go/ratelimit、GCRA 实现。
- 网关:Nginx
limit_req_zone、Envoylocal_rate_limit/global_rate_limit。
2. 熔断(Circuit Breaker):快速失败,避免雪崩
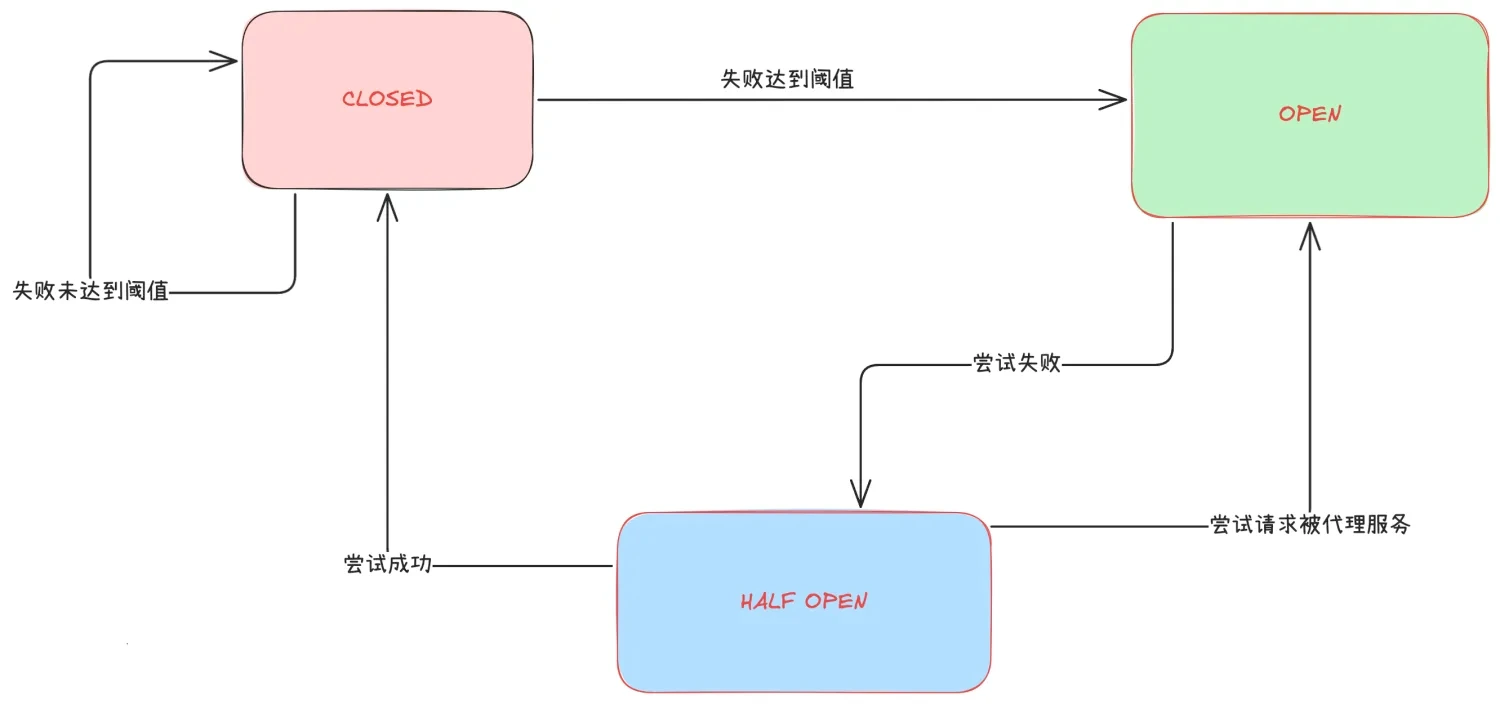
2.1 状态机与参数
熔断器遵循 Closed → Open → Half-Open 的三态机:
| 状态 | 行为 | 进入条件 | 退出条件 |
|---|---|---|---|
| Closed | 正常转发 | 初始 | 错误率 ≥ 阈值 |
| Open | 直接拒绝 | 错误率触发 | 经过 sleepWindow |
| Half-Open | 放少量请求探测 | sleepWindow 到期 | 探测成功 → Closed;失败 → Open |
参数建议
- 错误率阈值:50 %(电商)、80 %(内部工具)。
- 统计窗口:10 s(RT 低)~60 s(RT 高)。
- sleepWindow:5 s 起,按 99th RT 倍数递增。
2.2 实现对比
| 组件 | 语言 | 最新版本 | 维护状态 | 特性 |
|---|---|---|---|---|
| Resilience4j | Java 8+ | 2.2.0 | 活跃 | 函数式、Micrometer 指标、支持时间窗口和基于异常比例 |
| Sentinel | Java/Go | 1.8.7 | 活跃 | 流量治理一体化,支持热点、链路、集群熔断 |
| Hystrix | Java | 1.5.18 | 停止维护 | 仅修严重 bug,官方建议迁移 |
2.3 生产注意点
- 异常分类:只熔断
IOException、TimeoutException,不熔断业务异常(如 4xx)。 - 自适应熔断:Resilience4j 1.7+ 支持基于响应时间的自适应阈值。
- 探测流量:Half-Open 阶段可配置“每 5 s 放 3 个请求”,避免惊群。
- 事件通知:熔断状态变更推送到 Prometheus + Alertmanager,30 s 内完成告警。
3. 服务降级(Degradation):优雅地“减功能不减体验”
3.1 与熔断、限流的区别
- 限流:控制 入口流量。
- 熔断:控制 下游故障蔓延。
- 降级:控制 自身资源占用,主动关闭非核心功能。
3.2 降级策略
| 策略 | 触发条件 | 示例 |
|---|---|---|
| 静态默认值 | 配置中心开关 | 推荐服务返回空列表 |
| 缓存兜底 | 接口超时 | 商品详情返回 5 min 前的缓存 |
| 异步写 | 写库压力大 | 订单先写 MQ,后台异步落库 |
| 功能关闭 | 手动 / 自动 | 直播弹幕关闭,仅保留直播流 |
3.3 Sentinel 动态降级示例
@SentinelResource(value = "hotItems", blockHandler = "degradeHotItems", fallback = "cachedHotItems")public List<Item> hotItems(long categoryId) { return itemDao.topN(categoryId);}
public List<Item> cachedHotItems(long categoryId) { return cache.get("hot:" + categoryId, Duration.ofMinutes(5));}blockHandler:被限流/熔断时调用。fallback:任何异常(包括业务异常)触发,可做兜底数据。
4. 总结:三把锁如何协同
| 场景 | 第一优先级 | 第二优先级 | 第三优先级 |
|---|---|---|---|
| 突发流量 | 限流 | 熔断 | 降级 |
| 下游故障 | 熔断 | 降级 | 限流 |
| 大促高峰 | 降级 | 限流 | 熔断 |
口诀:“先降级保核心,再限流保稳定,最后熔断防雪崩”。